
Data silos occur when data is isolated within different departments or systems, making it difficult to access and share across teams within the organisation.
What is the impact of data silos?
This fragmentation can lead to several issues, including:
- Inefficiency: Teams spend excessive time locating and consolidating data from various sources.
- Inconsistent Data: Different departments may have conflicting versions of the same data, leading to inaccuracies and lack of trust in data.
- Limited Insights: Siloed data creates barriers that prevent comprehensive analysis. Teams can only see partial views of data rather than a complete picture, which limits their ability to gain cross-functional insights.
- Reduced Collaboration: Teams struggle to collaborate effectively when they cannot easily share data. The lack of seamless data sharing can lead to operational inefficiencies, miscommunication, and missed opportunities for innovation.
- Security: Data exported into .csv files and shared via email or stored in isolated data repositories is more problematic to monitor. Ultimately, data silos may weaken an organisation’s ability to protect sensitive data.
- Increased Costs: Data siloes may lead to higher costs due to the extra storage required to store the same data separately, the overhead of managing multiple databases, and costly integration processes.
Breaking down these silos is crucial for improving data accessibility, consistency, and collaboration, ultimately driving better business outcomes.
Example from the Automotive Industry
Consider a motor vehicle importer where different departments manage their data independently but require the same data for their reporting requirements. For instance:
- The pre-owned vehicles department: On a daily basis, extract dealer pre-owned sales data from their systems, input into Excel reports, and then build analytics for tracking promotions performance against target.
- The brand reporting team: This team receives data from the pre-owned vehicles department on a monthly basis, copies it, and integrates it into the overall brand performance reports for their team.
- The dealership network development team: Also receives the same data via email on a quarterly basis to use it for overall dealer performance reporting.
The process described involves multiple instances of data extraction, duplication, and manual handling, leading to inefficiencies and potential errors. The lack of a centralised data location makes it challenging for these departments to access and share data seamlessly.
How does Microsoft Fabric help centralise data?
Microsoft Fabric addresses these challenges by providing a unified data platform centralising data management and access. Here's how it works:
- Unified Data Platform: Fabric integrates various data services into a single platform, allowing users to access and manage data from one place.
- One Lake (Data Lake): One Lake is a centralised repository for the organisation’s analytics data. Departments can store, share, and access a single copy of the data in a governed and secure manner.
- Data Flows and Power Query: These tools enable users to automate data extraction, transformation, and loading (ETL) processes, reducing manual effort and ensuring data consistency.
- Copilot Integration: AI-powered features like Copilot assist users in summarising data, generating reports, and developing data models, making advanced data tasks accessible to everyone.
- Simplified Cost Structure: Fabric's pricing model is easy to understand and scalable, allowing departments to start small and expand as needed.
- Unified Security and Governance: Fabric helps organisations protect their data by centralising security, governance, and data monitoring. Role-based access control (RBAC) ensures users have appropriate permissions based on their roles.
In the automotive company example, Microsoft Fabric would enable the pre-owned vehicles department to manually upload or automate the extraction of their sales data to OneLake. This daily updated data would then be accessible—subject to user permissions—to the brand reporting and network development teams without duplication or manual handling. Each department can connect to the centralised data source, ensuring consistency and reducing inefficiencies.
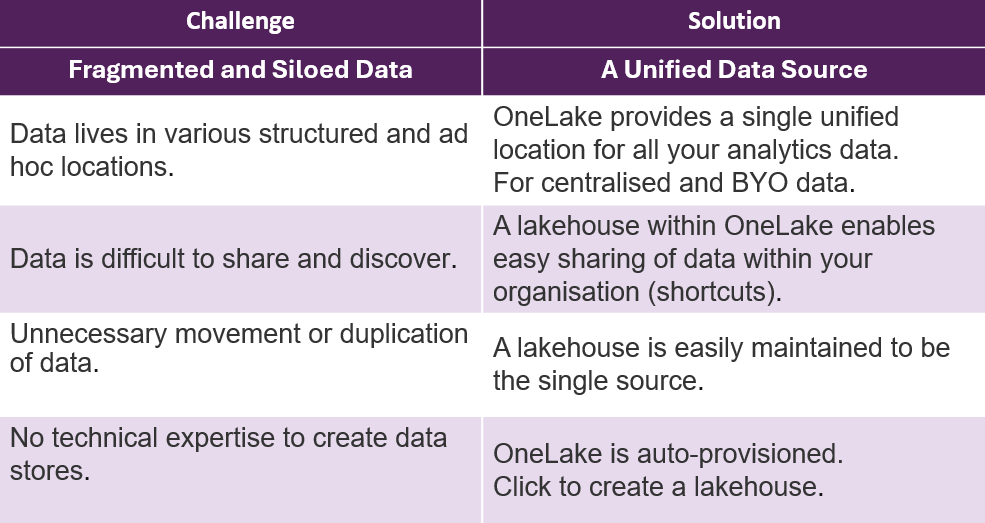
What are the benefits of a Unified Data Platform?
By centralising data management with Microsoft Fabric, organisations can achieve several benefits:
- Improved Data Accessibility: Data is easily accessible to all authorised users, regardless of their department.
- Enhanced Data Consistency: A single source of truth ensures that all users work with the same, accurate data.
- Increased Efficiency: Automated ETL processes and centralised data storage reduce manual effort and streamline workflows.
- Better Collaboration: Teams can collaborate more effectively when they can easily share and access data.
- Comprehensive Insights: Centralised data enables holistic analysis, leading to more informed decision-making.
Breaking down data silos with Microsoft Fabric empowers organisations to leverage their data more effectively, driving better business outcomes and fostering a data-driven culture.
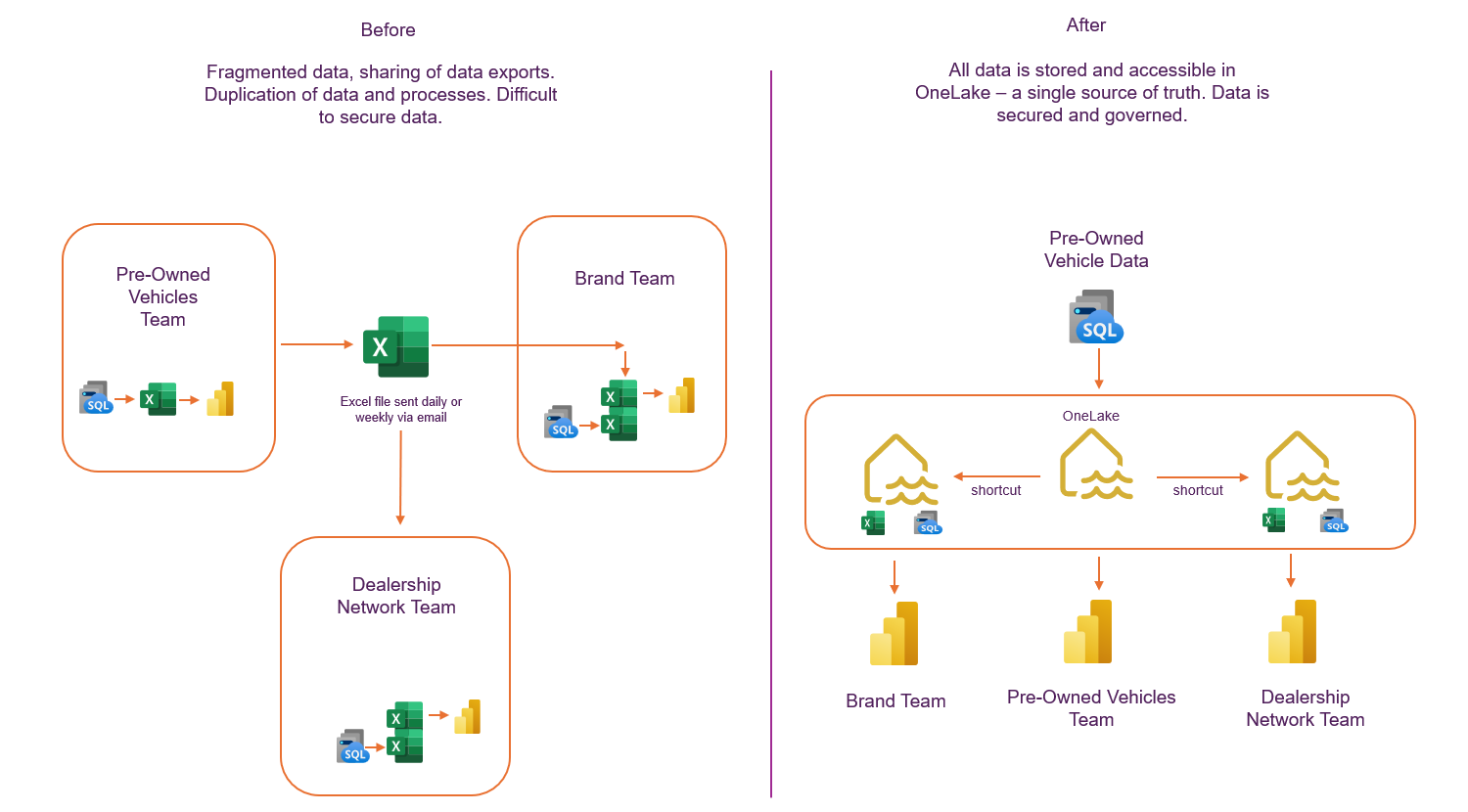
High-level data flow of the before and after of the automotive company example.
Are you interested in learning more about Microsoft Fabric?
Join us for part one in our webinar series about how to Unlock the next level of Power BI with Fabric: Unify all your analytics data.




